本記事は「彩雲天気の地理検索最適化(2): 行政区画検索」からの転載です。
彩雲天気アプリと API では、現在の緯度経度における気象警報情報(例:「強風青色警報」)を取得することができます。 各国・地域によって警報発令の規則は異なりますが、中国では行政区画レベルで発令されており、最小単位は県レベルの行政区画となっています。 そのため、実装においては緯度経度を行政区画レベルの情報に変換し、関連する警報情報を検索する必要があります。 過去数年間、このモジュールは何度もリファクタリングと改善を経験してきました。ここでは各バージョンの実装方法を共有します。
V1
彩雲天気アプリと彩雲天気データ API の初期ユーザーは、長い間、彩雲天気が表示する気象警報が実際の行政区画と一致していないことがあったことをご存知かもしれません。これはユーザー体験とビジネス顧客の使用に大きく影響を与える問題でした:
- 昌平にいるのに、海淀の警報を見ている
- 海淀学院路付近にいるのに、朝陽の警報を見ている
- 朝陽大悦城にいるのに、通州の警報を見ている
恥ずかしながら、この計算方法は非常に単純でした:各 adcode の中心点を反復処理して最も近い adcode を計算するという、単純明快な方法でした。前節の気象観測所データ検索と似ていて、理解は複雑ではありません。 当時のチームの状況により、2021 年までこの問題は解決できませんでした。 全体的な正確性の指標も評価されておらず、当時は楽観的に 70%〜80%程度と考えていました(大きな誤りでした)。
V2
その後、チームの成長とユーザーフィードバックの増加に伴い、この問題の解決に着手することを決定しました。 当時の考え方は、全国の各キロメートルグリッドを事前計算すれば十分な精度が得られるのではないかというものでした。 緯度経度の四角形グリッドを使うか、それとも他のものを使うか?
Grab の 2018 年 GopherChina 発表は参考となる情報を提供してくれました: Geohash は赤道地域で歪みが生じ、同じ解像度でも中緯度と赤道地域で表現される面積に大きな差が出ます。 これにより効果が悪くなります。中国本土は中緯度に位置していますが、南北の広がりも小さくないことを考慮すると、 同じ解像度で実際に表現される面積が近い方が良く、同じ解像度を使用できます。そのため Geohash は除外されました。
S2 地理インデックスシステムは私が長く注目してきたシステムで、以下の利点があります:
- 安定性:S2 は Google Maps で長年の実績がある
- アルゴリズム設計:親ノードは必ず正確に 4 つの子ノードのみを含む(後にこの点が非常に重要であることが分かります)
欠点:
- 完全な API 実装は C++のみ
- Go は最初からアルゴリズムを実装し、プロジェクトの活性度は懸念がある
一方、Uber H3 は真剣にオープンソース化に取り組んでおり(データ分析シーンで大量に使用)、各言語に既存のパッケージがあります。 検索してみると、Uber、Grab、DiDi はすべて六角形を地理インデックスとして使用しており、 私たちも既に一部のビジネスで本番環境で H3 を使用していました。そこで決定しました。 当時の見解では、地理データ処理においてこれらの配車会社により近く、距離/範囲に敏感で、境界にはそれほど敏感ではないと考えました。
H3 とは
H3 は地理インデックスシステムで、地球全体を異なる解像度で複数の六角形に分割します。
| 例 | 図 |
|---|---|
| ロサンゼルス市街地、画像は H3 公式サイトより |  |
| 米国本土の観測所の集約 |  |
| ニューヨークの郵便番号と H3 の比較、画像はZIP Codes vs H3より |  |
使用方法
ウェブからポリゴンファイルをダウンロードし、Uber H3 の Polygon Fill 方法を使用して、解像度を 9 に設定し、H3 小グリッドでポリゴン領域を埋めます。
赤は元のグリッド、青は集約後
公開データを利用して検証データセット A(緯度経度と adcode のみを含む)を構築したところ、第一世代の正確性は 50%程度でした。赤いグリッドは 90%以上で、効果は非常に顕著でした。 そのため、リリース後に v2.6 バージョンの API で行政区画レベル情報を外部に公開しました。
この実装の欠点は明らかでした:
- メモリ使用量が多い、200MB のメモリオーバーヘッド?
- Geo ポリゴンファイル、H3ID JSON ファイルの生成、メンテナンスは手作業で実装され、エンジニアリング的ではない
- ファイル自体が大きく、20MB 近く、コードとデータの分離が実現できていない
V3
2021 年 11 月末、ユーザーから地域の警報が受信できないという報告がありました。近隣のグリッドデータを確認したところ、予期せぬ状況が見つかりました:
隣接グリッド
ユーザーが行政区画の境界線上にいる場合、グリッドの集約により形状の詳細が失われ、 ユーザーの位置が隣接するグリッドに分類されてしまいました。特に H3 の上層と下層のカバー領域は近似的で、 完全な包含関係ではないため、境界部分でグリッドが正確ではなくなり、この方法は使えません:
正確な境界が必要なユースケースでは、アプリケーションは階層的な問題を慎重に扱う必要があります。 これは、階層を地理的なものではなく論理的なものとして扱うことで実現できます。 もう一つの有用なアプローチは、より正確なポイントインポリゴンチェックに加えて、 グリッドシステムを最適化として使用することです。

最初は解像度を上げて、より細かい粒度にしましたが、結果は依然として包含できませんでした。 境界範囲の詳細は集約が難しく、数十メートルレベルの精度まで上げない限り、そしてそれはメモリ圧力が大きすぎました。 ポリゴン検索という方法しか残されていませんでした。
理論的に、点がポリゴン内部にあるかどうかを判定するには?この問題はPoint in polygon(PIP)と呼ばれています。 数学的なアルゴリズムはRay castingと呼ばれ、判定条件は: その点から放射される線とポリゴンの交点数が常に偶数でない場合、その点はポリゴン内部にあります:

しかし、コードに落とし込む際には、アルゴリズムだけでなく、様々な境界条件や実行効率などを考慮する必要があり、成熟した信頼できるソリューションが必要でした。 コミュニティのオープンソースアルゴリズム実装を調査した結果、Tile38 データベースの底層で使用されている地理計算コンポーネントが最も私たちのニーズに合っていることが分かりました。 特に作者が 2018 年に開発したポリゴンの事前インデックス化の最適化により、 ポリゴンデータを保存する際に RTree で構築されたインデックス構造も保存し、 ポリゴン全体を分割統治し、境界を多数の小さな四角形に分解することで、より高速な Point in Polygon 判定を実現しました。 そのため、先人の基礎の上に、行政区画ポリゴンデータを利用して、速度がそれほど遅くない高精度の緯度経度から行政区画への変換機能を実現しました。
事前に学習しておきたかった資料があるとすれば、それはRFC 7946です。GeoJSON のファイル定義全体がこのファイルで明確に定義されています。
例えば、行政区画に 2 つのポリゴンがある場合の処理について、最初は気付きませんでしたが、より多くのことを考慮する必要がありました。例えば青山湖区:
青山湖
その後、時間の経過とともに検証データセットを再構築し、過去の実装と最新バージョンを比較しました:
| バージョン | 正確性 |
|---|---|
| v1 | 56.5% |
| v2 | 88.8% |
| v3 | 97.4% |
本番環境:
- メモリ使用量 728MB
- 起動時間 5.6s、元の 5.2s から+0.4s
- API レイテンシー 1.9ms、元の 1.5ms から+0.4ms
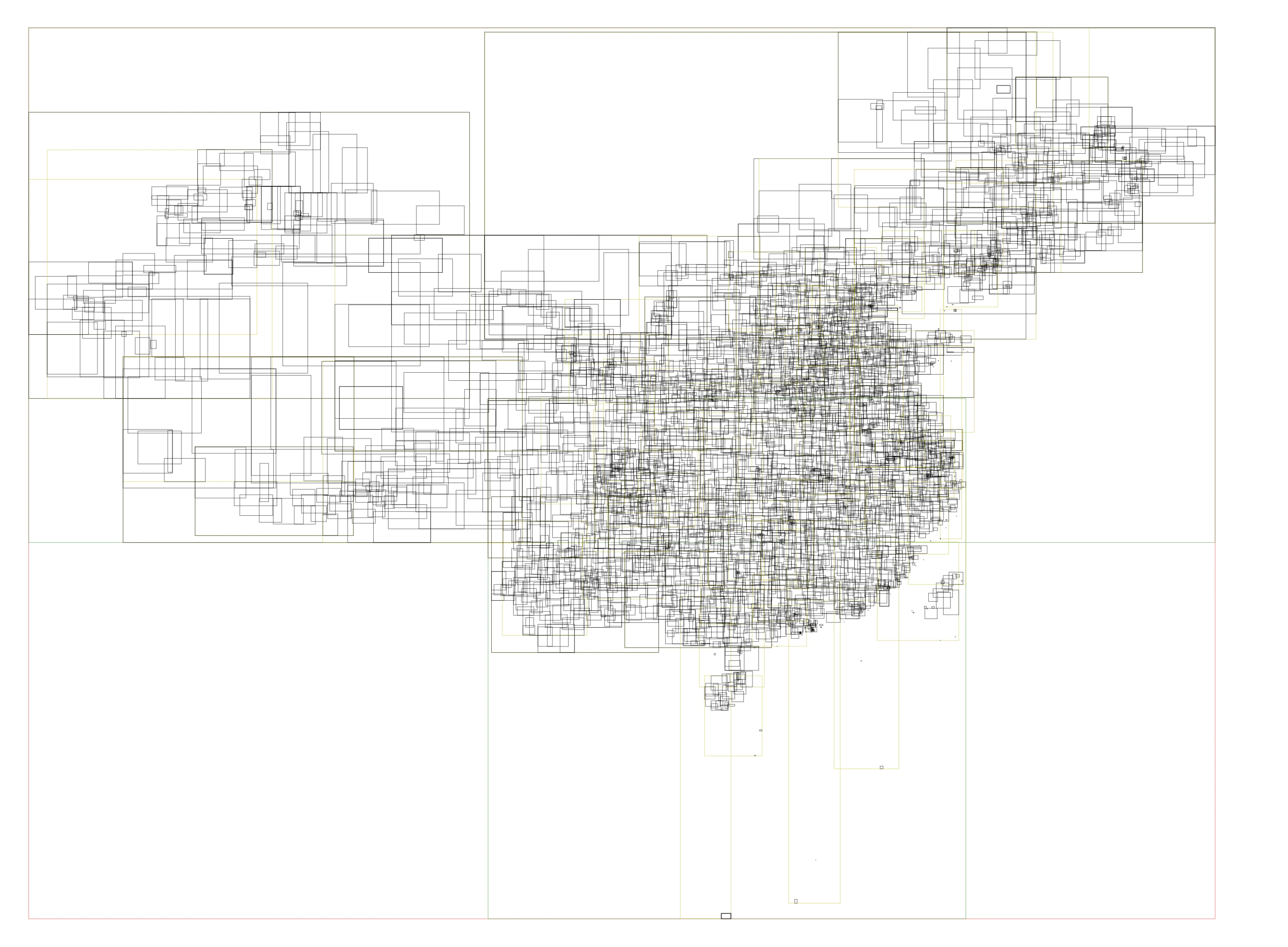
以前の H3 インデックスの構築と map の直接検索に比べて、現在は射線法を実装する必要があり、処理時間は大幅に増加しました。 単一の検索に約 100000 ns かかり、高並列シナリオで CPU リソースを多く消費するため、 全国数千のポリゴンの外層に RTree インデックスを導入し、完全な反復処理を避けました。図に示すように、中国の行政区画の RTree インデックス情報:

RTree インデックスを追加することで、数十のポリゴンデータのみを判定すれば良くなり、全体の処理時間は 80%減少し、約 20000 ns で行政区画情報を取得できるようになりました。