GHCNdデータセットの正式名称はGlobal Historical Climatology Network daily(世界歴史気候ネットワーク日次データ)です。
これはNOAAが公開している世界中の観測所データセットで、1763年からのデータが含まれており、世界中の約12万の気象観測所からの日々の気象観測データが収録されています。
GHCNdデータセットの月次集計バージョンはGlobal Historical Climatology Network monthly(世界歴史気候ネットワーク月次データ)です。
週末にこのデータセットの統計分析を行ったので、その処理の流れを記録しておきます。
まず、データを同期します。このデータセットはNOAA自身のサーバーとAWS/GCPのパブリックデータセットの両方に保存されています。
簡単にするため、AWSのデータセットを選びました。最初はAWS CLIを使用してデータを同期しましたが、JuiceFSを使用して同期することもできます。
1
2
3
4
5
6
7
| # AWS CLIによる同期
aws s3 cp --region us-west-2 --no-sign-request s3://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt data/ghcnd-stations.txt
aws s3 cp --recursive --region us-west-2 --no-sign-request s3://noaa-ghcn-pds.s3.amazonaws.com/parquet/by_station data/parquet/by-station
# JuiceFSによる同期
juicefs sync s3://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt data/ghcnd-stations.txt
juicefs sync s3://noaa-ghcn-pds.s3.amazonaws.com/parquet/by_station data/parquet/by-station
|
その後、日次と月次のデータ統計作業を行いました。
核心はPolarsを利用して、指定した時間範囲で必要な統計情報を計算することです。例えば、日次の統計計算は以下のようになります:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # 日次統計の計算
daily_df = (
df.group_by_dynamic("DATE", every="1d")
.agg(
pl.col("DATA_VALUE").mean().alias(f"{element}_MEAN"),
pl.col("DATA_VALUE").min().alias(f"{element}_MIN"),
pl.col("DATA_VALUE").max().alias(f"{element}_MAX"),
pl.col("DATA_VALUE").quantile(0.1).alias(f"{element}_P10"),
pl.col("DATA_VALUE").quantile(0.2).alias(f"{element}_P20"),
pl.col("DATA_VALUE").quantile(0.5).alias(f"{element}_P50"),
pl.col("DATA_VALUE").quantile(0.8).alias(f"{element}_P80"),
pl.col("DATA_VALUE").quantile(0.9).alias(f"{element}_P90"),
pl.col("DATA_VALUE").sum().alias(f"{element}_SUM"),
pl.col("DATA_VALUE").count().alias(f"{element}_COUNT"),
)
.collect()
)
|
そして、Matplotlibを使って可視化しました:
処理コードはGitHubで公開しています:ringsaturn/ghcn-showcases。
また、GitHub Pagesで一部の観測所の統計情報を表示する静的ページも提供しています:ghcn-showcases。
ウェブページの表示プレビュー:
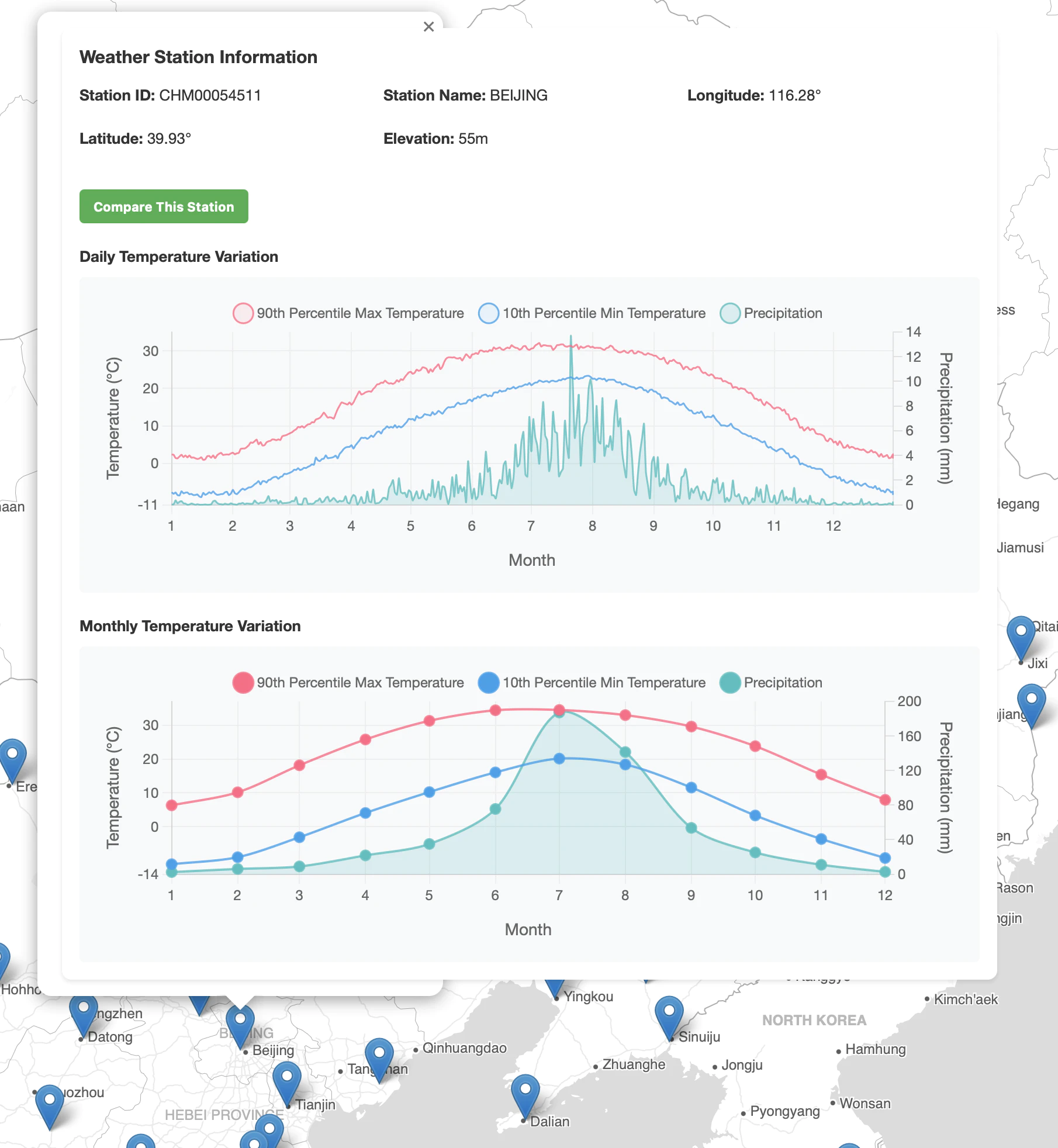
北京の表示プレビュー
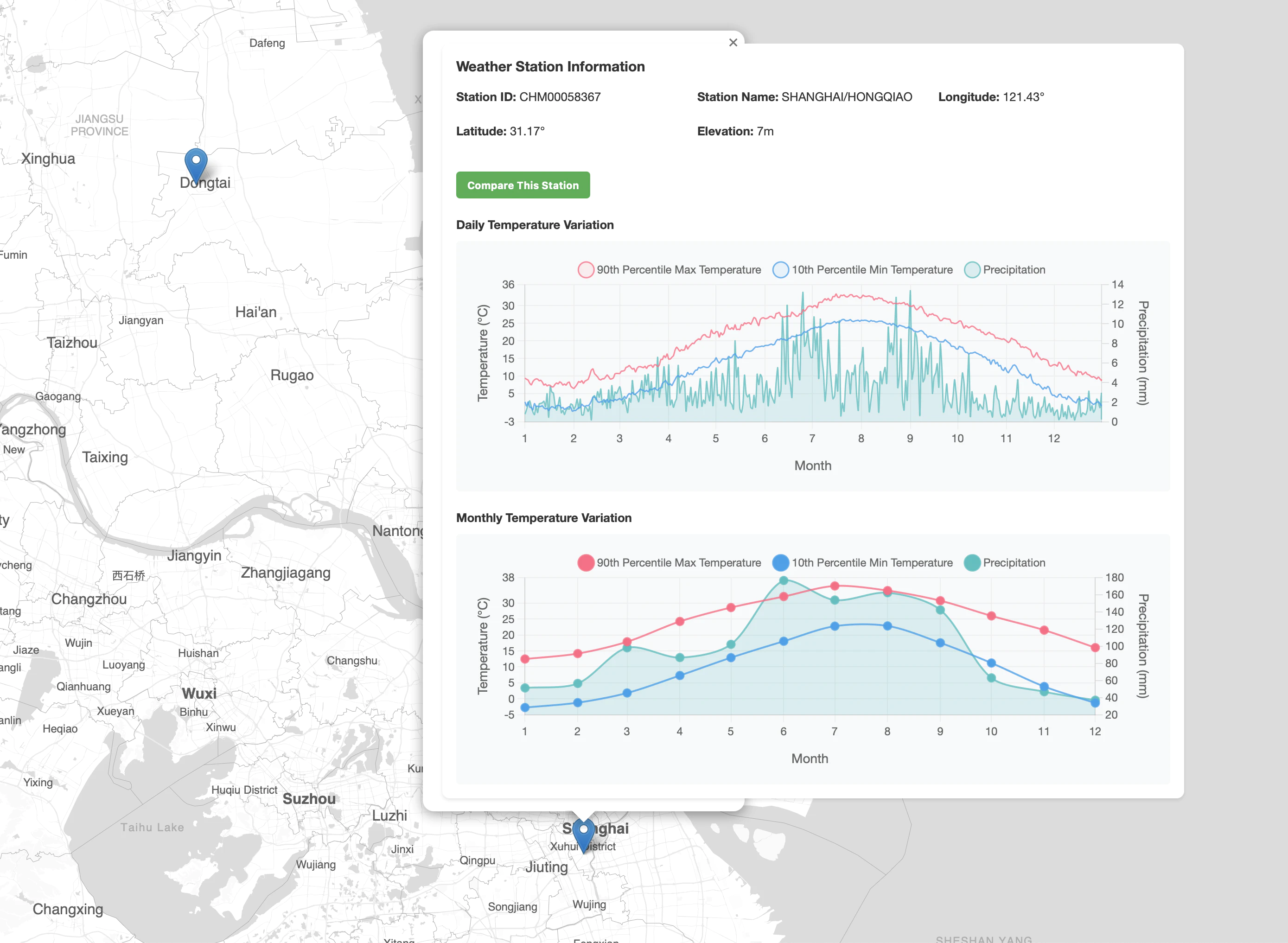
上海の表示プレビュー
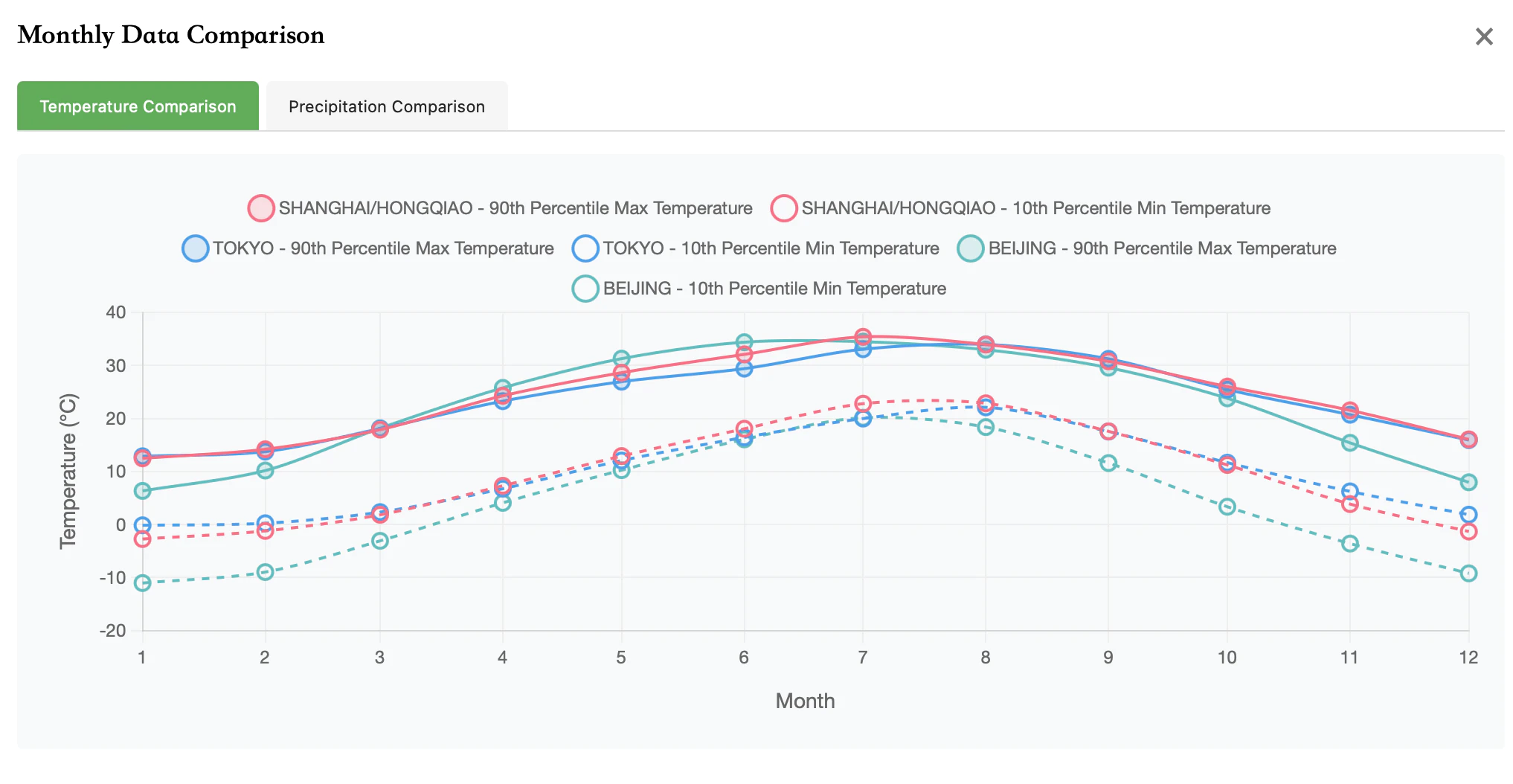
北京/上海/東京の気温比較

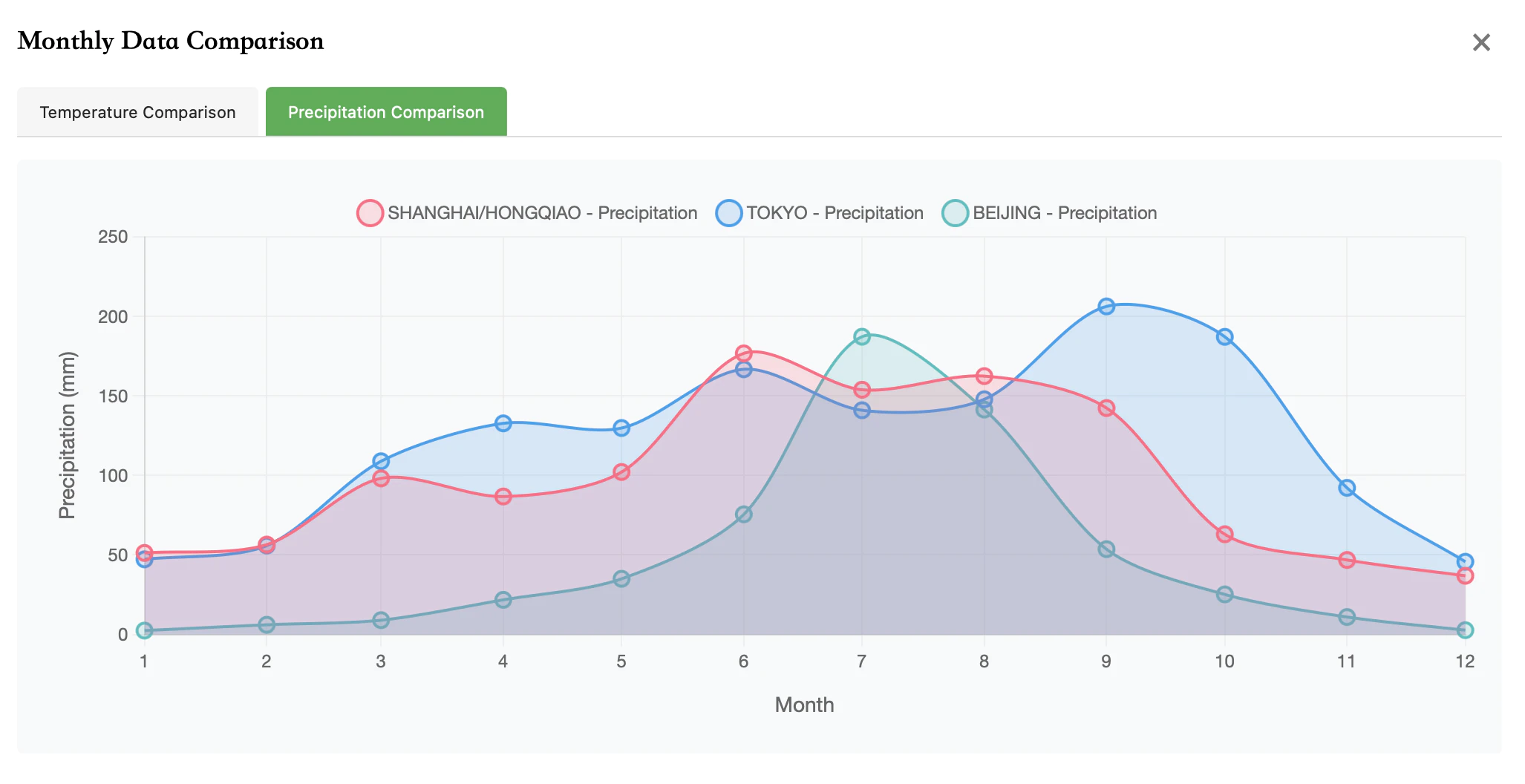
北京/上海/東京の降水量比較