GHCNd 数据集的全名是 Global Historical Climatology Network daily。
是 NOAA 公开的全球站点观测数据集,数据从 1763 年开始,包含了总计 12 万个气象站点的每日气象观测数据。
GHCNd 数据集的月度汇总版本是 Global Historical Climatology Network monthly。
周末的时候对这个数据集的数据做了一些统计,记录下大致的处理流程。
首先是同步数据,这个数据集在 NOAA 自己的服务器和 AWS/GCP 的公共数据集上都有存储。
我为了简单起见,选择了 AWS 上的数据集。我最开始用的是 AWS CLI 进行同步,也可以用 JuiceFS 进行同步。
1
2
3
4
5
6
7
| # Sync via AWS CLI
aws s3 cp --region us-west-2 --no-sign-request s3://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt data/ghcnd-stations.txt
aws s3 cp --recursive --region us-west-2 --no-sign-request s3://noaa-ghcn-pds.s3.amazonaws.com/parquet/by_station data/parquet/by-station
# Sync via JuiceFS
juicefs sync s3://noaa-ghcn-pds.s3.amazonaws.com/ghcnd-stations.txt data/ghcnd-stations.txt
juicefs sync s3://noaa-ghcn-pds.s3.amazonaws.com/parquet/by_station data/parquet/by-station
|
随后则是进行了逐日和逐月级别的数据统计工作。
核心是利用 Polars 在指定的时间范围计算需要的统计信息,例如逐日的统计计算:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| # Calculate daily statistics
daily_df = (
df.group_by_dynamic("DATE", every="1d")
.agg(
pl.col("DATA_VALUE").mean().alias(f"{element}_MEAN"),
pl.col("DATA_VALUE").min().alias(f"{element}_MIN"),
pl.col("DATA_VALUE").max().alias(f"{element}_MAX"),
pl.col("DATA_VALUE").quantile(0.1).alias(f"{element}_P10"),
pl.col("DATA_VALUE").quantile(0.2).alias(f"{element}_P20"),
pl.col("DATA_VALUE").quantile(0.5).alias(f"{element}_P50"),
pl.col("DATA_VALUE").quantile(0.8).alias(f"{element}_P80"),
pl.col("DATA_VALUE").quantile(0.9).alias(f"{element}_P90"),
pl.col("DATA_VALUE").sum().alias(f"{element}_SUM"),
pl.col("DATA_VALUE").count().alias(f"{element}_COUNT"),
)
.collect()
)
|
然后利用 Matplotlib 进行可视化:
处理的代码开源在 GitHub 上,见 ringsaturn/ghcn-showcases。
另外也在 GitHub Pages 上提供了一个静态页面展示部分站点的统计信息,见 ghcn-showcases。
网页效果预览:
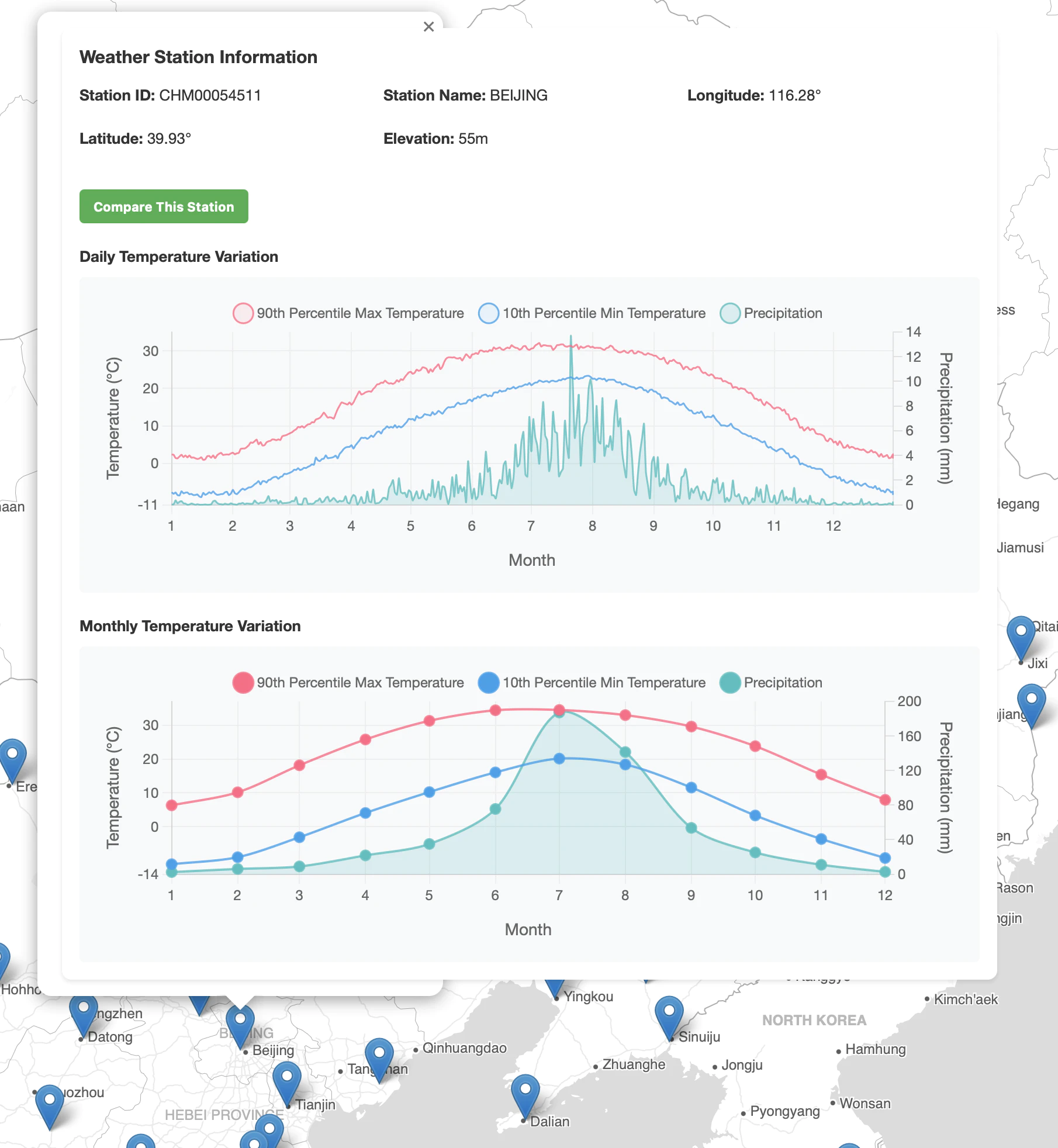
北京展示效果预览
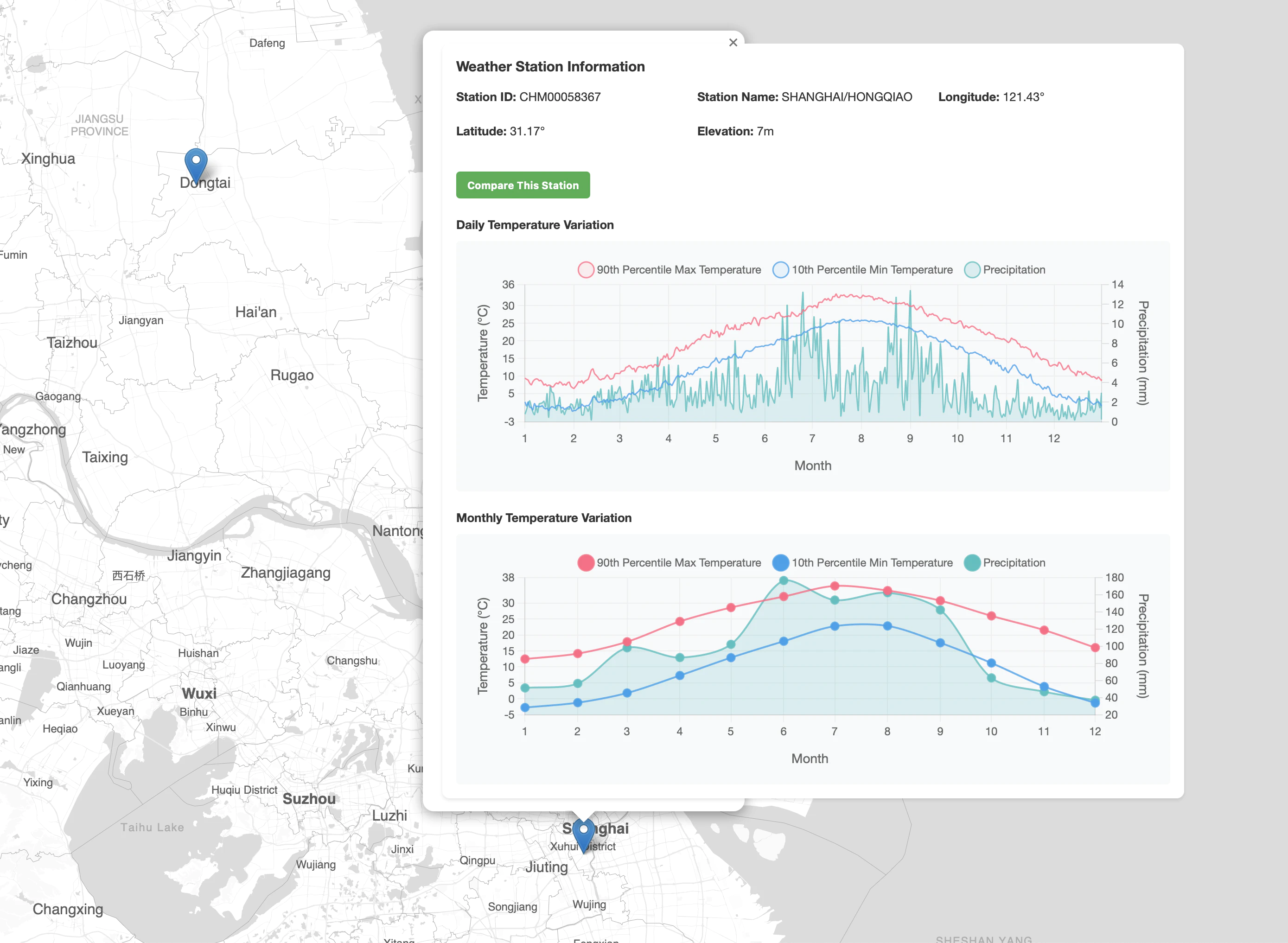
上海展示效果预览
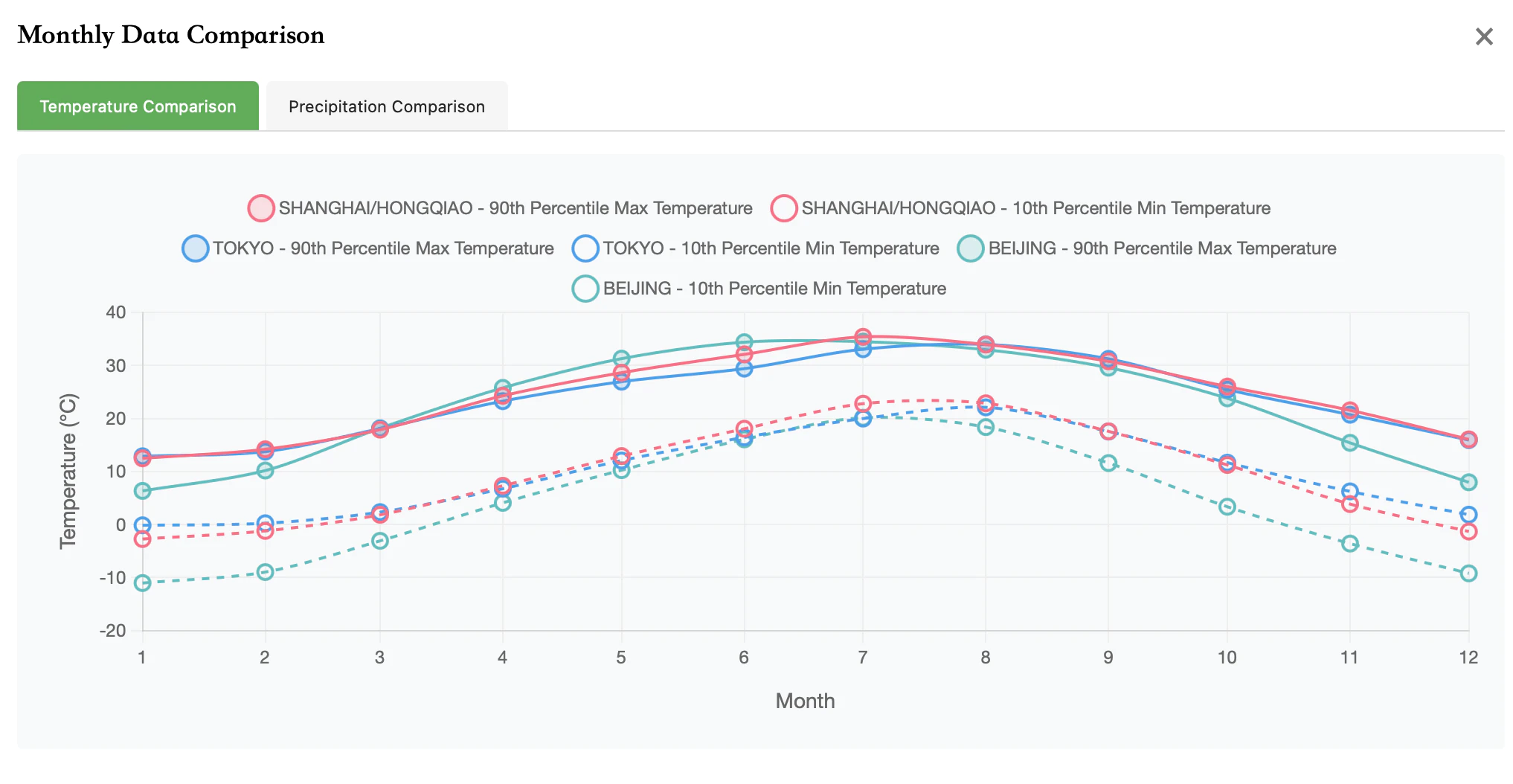
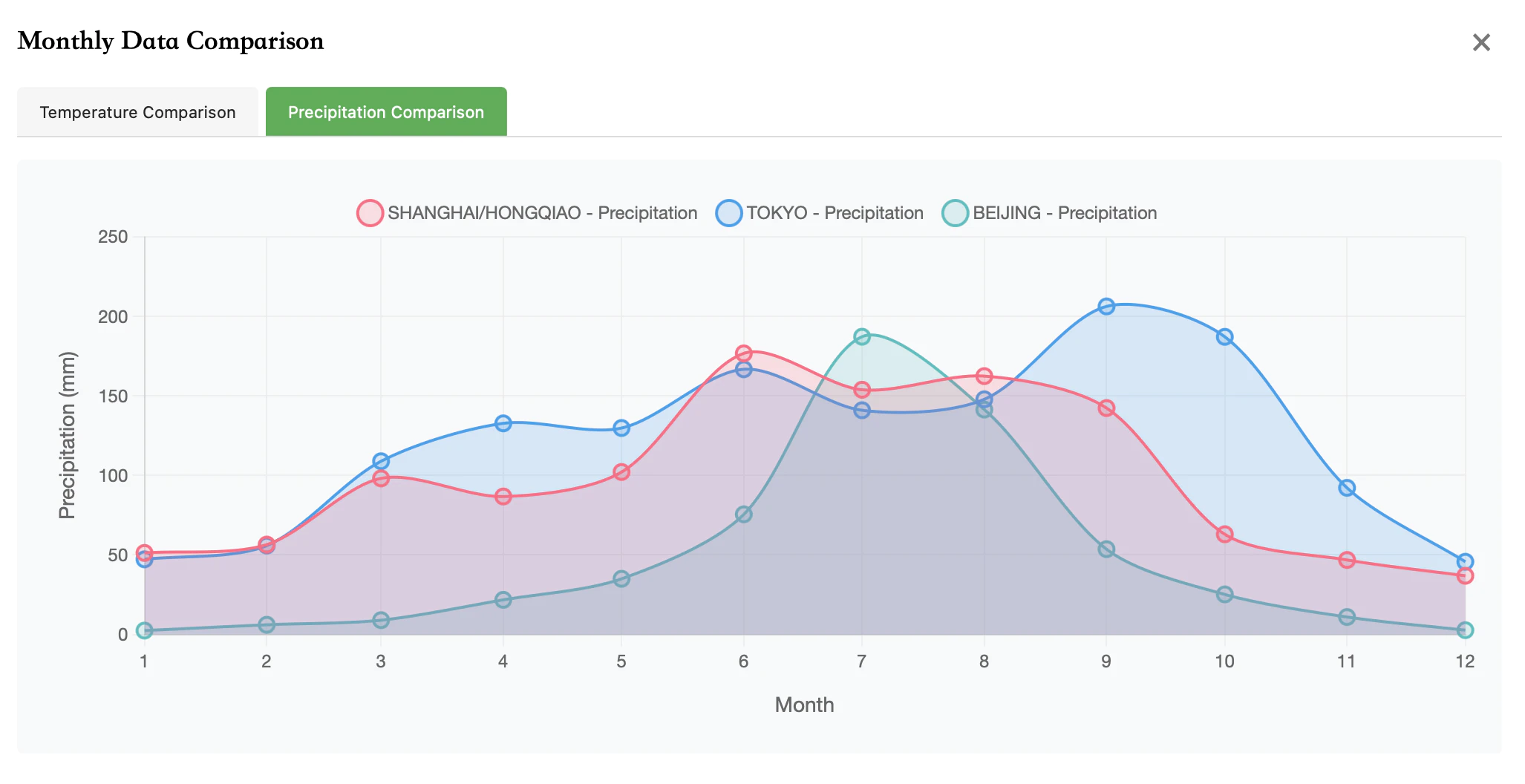
对比北京/上海/东京的温度

对比北京/上海/东京的降水量