在彩云天气 App 和 API 里可以获取到当前经纬度的气象预警信息,比如「大风蓝色预警」。 不同国家地区的预警发布规则不一样,在中国是按照行政区划层级来发布的,其中最小到县级行政区。 所以在实现中,需要将经纬度转换成行政区划层级信息,再查找相关的预警信息。 在过去几年中,这部分模块经历了多次重构和完善,在此分享下每个版本的实现方式。
V1
彩云天气 App 和彩云天气数据 API 的早期用户可能知道,在很长的时间里, 彩云天气展示的气象预警往往和所在的行政区划并不一致。这一点是非常影响用户体验和 toB 客户使用的:
- 人在昌平,看的是海淀预警
- 人在海淀学院路附近,看的是朝阳预警
- 人在朝阳大悦城,看的是通州的预警
说来惭愧,这个计算思路非常简陋: 遍历各个 adcode 中心点计算最近的 adcode 是哪一个,简单粗暴。 和上一节的气象站数据查询有相似之处,理解起来不复杂。 受限于当时的团队情况,2021 年之前没有解决的方法。 整体正确率指标也没有评估,当时乐观认为 70%~80% 左右(大错特错)。
V2
后来随着团队成长以及用户反馈的增加,我们决定开始着手解决这个问题。 当时的思路是如果将全国每个公里网格预计算好,这样是不是就够准了。 用经纬度的四边形网格,还是用其他的?
Grab 2018 年的 GopherChina 分享提供了一个参考信息: Geohash 在赤道地区是会有畸变的,同等分辨率表示的面积在中纬度和赤道地区差异很大。 导致效果会更不好。 虽然中国大陆区域在中纬度,但是考虑到南北跨度也不小, 最好同等分辨率实际表示的面积是接近的,这样可以用同样的分辨率。 所以 Geohash 被排除了。
S2 地理索引系统是我关注很久的系统,优势是:
- 稳定:S2 经受了 Google Maps 多年的考验
- 算法设计:父节点一定能恰好只包含四个子节点(事后会看这一点非常重要)
缺点:
- 完整 API 实现的只有 C++
- Go 是从头实现算法,项目活跃度堪忧
相比之前,Uber H3 是在认真做开源(本身在数据分析场景有大量使用)。并且各个语言都有现成的包。 搜索下发现 Uber、Grab、滴滴都在用六边形做地理索引, 而且我们已经在生产环境里用过了部分业务用过了 H3。 那就决定了。 当时的观点是,我们在地理数据处理上和这些打车公司更接近,对距离/范围敏感,对边界不那么敏感。
H3 是什么
H3 是一种地理索引系统,将全球划分成了在不同分辨率上划分成了若干个六边形。
| 示例 | 图 |
|---|---|
| 洛杉矶市区,图片来自 H3 官网 |  |
| 对美国本土观测站做聚合 |  |
| 纽约邮政编码和 H3 对比, 图片来自 ZIP Codes vs H3 |  |
怎么用
从网上下载多边形文件,用 Uber H3 的 Polygon Fill 方法,分辨率设置成 9, H3 小网格填充多边形区域。
红色的是原始网格,蓝色是聚合后的
我们利用公开的数据构建了一个验证数据集 A(只包含经纬度和 adcode),发现第一代的正确率在 50% 左右。 红色网格是 90%+,效果非常显著。 于是上线后我们还在 v2.6 版本的 API 里对外暴露了行政区划层级信息。
这个实现的缺点是很明显的:
- 内存占用较大,200MB 内存开销?
- Geo 多边形文件、H3ID JSON 文件的生成、维护是手工实现,不是那么工程化
- 文件本身较大,不到 20MB,没有实现代码和数据的分离
V3
2021 年 11 月底,有用户反馈说收不到当地的预警信息,我们检查了附近的网格数据发现了意外的情况:
临近网格
用户在行政区划的边界线上,因为网格聚合的原因,整个形状的细节丢失了, 导致用户所在地方被归类到另一个旁边的网格里。 特别是 H3 上层和下层覆盖的区域是近似的,不是完整的包含关系, 所以在分界处网格不会那么准确,所以不能用这个方式做:
In use cases where exact boundaries are needed applications must take care to handle the hierarchical concerns. This can be done by taking care to use the hierarchy as a logical one rather than geographic. Another useful approach is using the grid system as an optimization in addition to a more precise point-in-polygon check.

最开始尝试了提高了分辨率,颗粒度更细,结果依旧无法包含, 因为边界范围的细节很难被聚合出来,除非精度提高到几十米的水平,而这带来的内存压力太大了。 只剩下啃多边形搜索这个思路了。
理论上的如何判断一个点是否在多边形内部呢?这个问题学名叫 Point in polygon 简称 PIP。 数学上的算法叫 Ray casting 判定条件是: 从该点放出的射线,与多边形的交点数量只要永远不为偶数,就是在多边形内部的:

但是落地到代码上,需要的不仅仅是算法,要考虑各种边界条件,执行效率等,需要一个成熟可靠的方案。 我们调研了一些社区开源的的算法实现,发现最符合我们需求的是 Tile38 数据库底层用的地理计算组件。 特别是作者在 2018 年开发了对多边形做预索引的优化, 在存储多边形数据的同时也存储了基于 RTree 构造的索引结构, 将整个多边形分而治之,把边界拆成了一堆小的四边形,从而实现了更快的 Point in Polygon 判断。 所以我们在前人基础上,利用行政区划多边形数据实现了速度不算太慢的高精度经纬度转行政区划功能。
如果说有什么是我希望当时提前学习下的资料,那就是 RFC 7946。 GeoJSON 的整个文件定义都通过这个文件定义清晰了。
比如处理一个行政区划有两个多边形的时候会考虑得更多一些,最开始做的时候并没有注意到这一点,比如青山湖区:
青山湖
后来随着时间推移我们重新构建了一次验证数据集,并将历史的实现和最新版本做了对比:
| Version | 正确率 |
|---|---|
| v1 | 56.5% |
| v2 | 88.8% |
| v3 | 97.4% |
生产环境:
- 内存占用 728MB
- 启动耗时 5.6s,原 5.2s,+0.4s
- API 延迟 1.9ms,原 1.5ms, +0.4ms
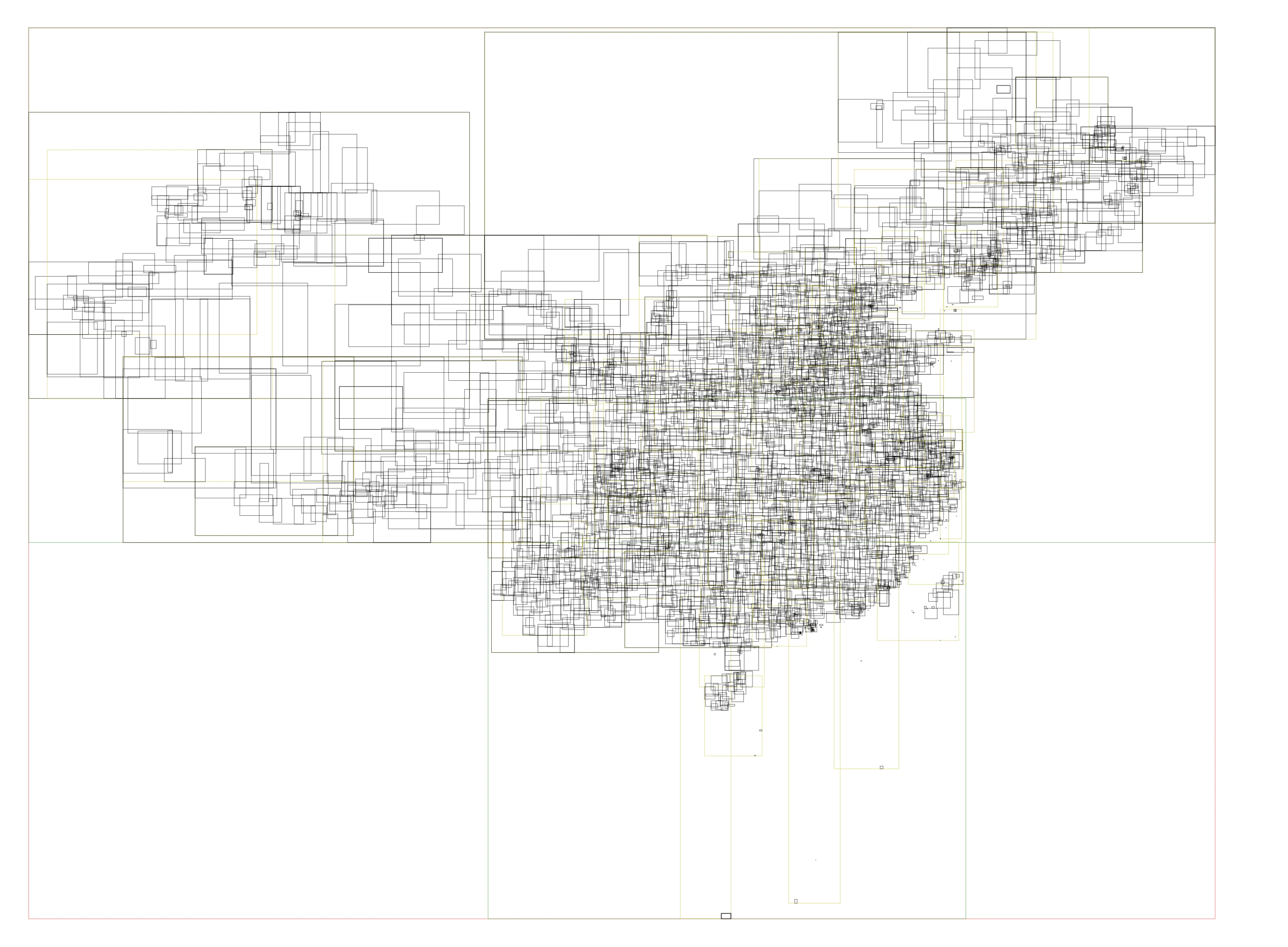
相比于原来的构造 H3 索引,然后直接查 map,现在需要用射线法实现,耗时是增加了不少。 单次查询耗时在 100000 ns 左右,并且在高并发场景下占用了太多的 CPU 资源, 我们在所有多边形的外层又引入了一层 RTree 索引,从而避免了完整遍历全国数千个多边形。 如图所示中国行政区划的 RTree 索引信息:

增加了 RTree 索引只需要判断几十个多边形数据即可识别,整体耗时下降了 80%, 20000 ns 左右就能获取到行政区划信息。